中心極限定理の気持ちをPythonで表現してみる
中心極限定理の気持ちをPythonで書いてみます。 中心極限定理とは、独立同分布に従う確率変数列の部分和は正規分布に分布収束するという定理です。 言い換えると、標本サイズが大きくなるに従って、標本平均は正規分布に近づくと解釈できます。
ここで、サイコロを例に考えると、𝑛 個のサイコロの出目の平均値の分布を求めると、𝑛 が大きくなるに従ってサイコロの出目の平均の分布が正規分布っぽくなる、ということです。実際にPythonで書いてみます。
サイコロ2個を10,000回投げる
まずはサイコロ2個を10,000回投げる操作を考えましょう。
このとき、2個の出目の平均値(2と3なら2.5、6と6なら6、...)を記録しておき、10,000個の平均値をヒストグラムにします。
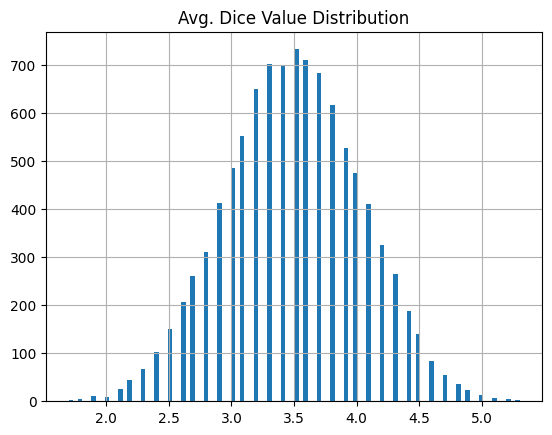
from scipy import stats import numpy as np import pandas as pd import random # 2個のサイコロを10,000回振る # 2個の出目の平均値(2と3なら2.5、6と6なら6、...)を記録しておき、10,000個の平均値をヒストグラムにする n = 2 avg_dice_value = [] for k in range(10000): dice_value = [] for i in range(n): dice_value.append(random.randint(1,6)) avg_dice_value.append(np.mean(dice_value)) pd.DataFrame(avg_dice_value).rename(columns={0: 'Avg. Dice Value Distribution'}).hist(bins=100)
結果はこんな感じ。まあ...正規分布っぽくはないかな?
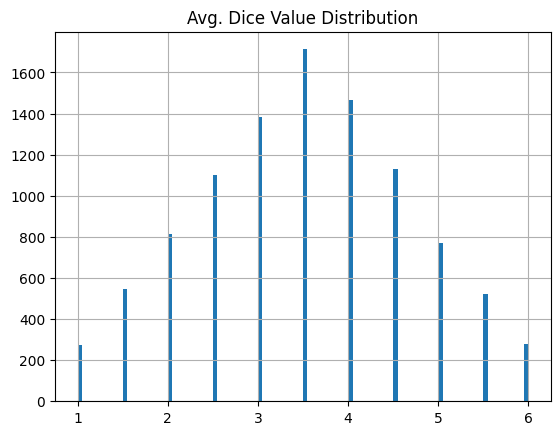
サイコロ3個を10,000回投げる
次に、サイコロの数を3個に増やします。
# 3個のサイコロを10,000回振る n = 3 avg_dice_value = [] for k in range(10000): dice_value = [] for i in range(n): dice_value.append(random.randint(1,6)) avg_dice_value.append(np.mean(dice_value)) pd.DataFrame(avg_dice_value).rename(columns={0: 'Avg. Dice Value Distribution'}).hist(bins=100)
結果、ちょっと正規分布っぽさが増しました。
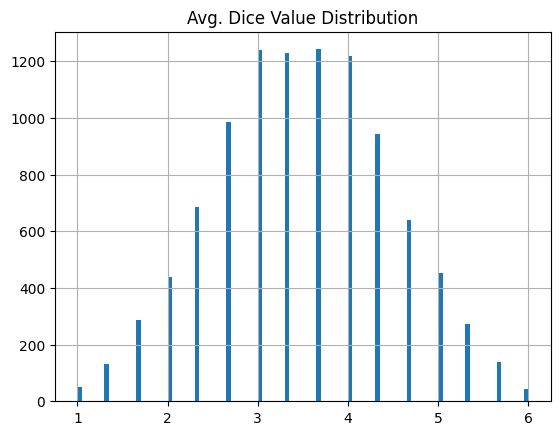
サイコロ4個を10,000回投げる
サイコロが4個の場合。
# 4個のサイコロを10,000回振る n = 4 avg_dice_value = [] for k in range(10000): dice_value = [] for i in range(n): dice_value.append(random.randint(1,6)) avg_dice_value.append(np.mean(dice_value)) pd.DataFrame(avg_dice_value).rename(columns={0: 'Avg. Dice Value Distribution'}).hist(bins=100)
おお、かなり正規分布っぽいぞ!
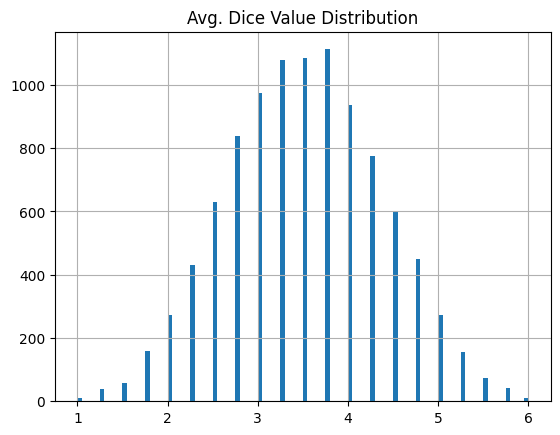
サイコロ5個を10,000回投げる
# 5個のサイコロを10,000回振る n = 5 avg_dice_value = [] for k in range(10000): dice_value = [] for i in range(n): dice_value.append(random.randint(1,6)) avg_dice_value.append(np.mean(dice_value)) pd.DataFrame(avg_dice_value).rename(columns={0: 'Avg. Dice Value Distribution'}).hist(bins=100)
5個まで増やすとかなり正規分布に近い。
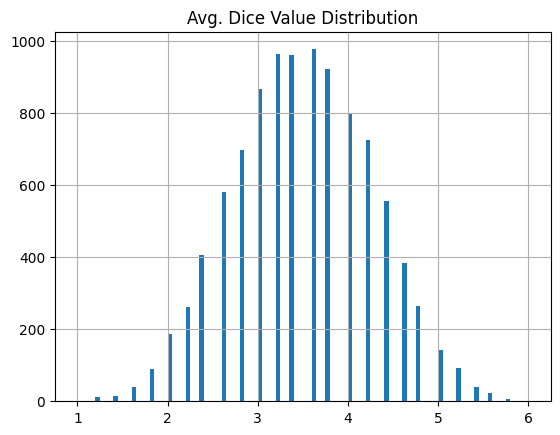
サイコロ10個を10,000回投げる
最後にサイコロを10個に増やします。
# 10個のサイコロを10,000回振る n = 10 avg_dice_value = [] for k in range(10000): dice_value = [] for i in range(n): dice_value.append(random.randint(1,6)) avg_dice_value.append(np.mean(dice_value)) pd.DataFrame(avg_dice_value).rename(columns={0: 'Avg. Dice Value Distribution'}).hist(bins=100)
もうほとんど正規分布に見えます。
まとめ
𝑛 個のサイコロの出目の平均値の分布をPythonで描いてみました。 サイコロ2個だと正規分布に似ているとは言えませんでしたが、2個から3個, 4個, ...と増やしていくと、だんだん正規分布に近づいていく様子がわかりました。たった10個まで増やしただけで、かなり正規分布に近い分布になったのはちょっと驚きでしたね。
【Python】NetworkXで友達の友達を可視化する方法
NetworkXを使ってSNSの分析をするときに便利かもしれない。
誰かの友達の友達をリストアップして可視化する方法です。
やり方は簡単で、最短経路長が2の人(1は友達)を探してくれば良いわけです。
例として、Zacharyの空手クラブを用います。
import networkx as nx G = nx.karate_club_graph() pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color="skyblue", font_color="black")

single_source_shortest_path_length を使って、指定したノードから各ノードへの最短経路長を調べます。
最短経路長 <= 2 とすれば、友達の友達までをリストアップできます。
# 1番の人を指定 i = 1 shortest_path_length = nx.single_source_shortest_path_length(G, i) # 最短経路長2以内のnodeを取り出す subset = {key:value for key, value in shortest_path_length.items() if value <= 2} subset = list(subset) # 色指定 color_map = [] for node in G.nodes(): if node == i: color_map.append('red') elif node in subset: color_map.append('orange') else: color_map.append('skyblue') pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")

これで1番の人の友達の友達までを可視化できました。
【Python】pandasでLAG / LEAD OVER PARTITION BY したいとき【SQL】
SQL書きすぎてるとpandasの書き方わからなくなる。
pandasでSQLの
LAG(value) OVER(PARTITION BY class ORDER BY value)
のような処理をどうやって書くのか?
groupbyとshiftを使えば一発です。LEAD()の場合はshift(-1)でOK。
import pandas as pd df = pd.DataFrame({ 'class': ['A', 'A' ,'A' ,'B' ,'B' ,'B'], 'value': [1, 2, 3, 4, 5, 6]} ) df_lag = pd.DataFrame(df.groupby(['class']).shift(1)) df_lag = df_lag.rename(columns={'value': 'lag_value'}) pd.concat([df, df_lag], axis=1)
> output class value lag_value 0 A 1 NaN 1 A 2 1.0 2 A 3 2.0 3 B 4 NaN 4 B 5 4.0 5 B 6 5.0
ネットワーク分析を用いて感染症の制御を考えてみる(経済セミナー 2020年12月・2021年1月号より)
ここでは、経済セミナー 2020年12月・2021年1月号に掲載のあった「中心性を使った感染症の制御(小蔵正輝)」という記事を、実際にPythonで(NetworkXを使って)コードを書きながら解説します。
以下で説明するような問題設定下においては、ネットワークの中心性を上手く使うことで感染症の拡大を抑えられるという、なかなか面白い内容でした。
NetworkXの勉強がてらコードを書いていきたいと思います。
問題設定
ある社会集団において、社会的なつながりを介して感染症が広がる状況を考えます。
家族や友達にしか感染症が伝染らないというような状況ですね。
そのような状況下で、「ワクチン接種を受けられる人数が限られているとき、ネットワーク内の誰にワクチンを打てば感染拡大を抑えられるか?」というのがここで考える問題です。
感染のルール
感染症が伝播するルールを設定します。
経済セミナーの記事からそのまま引用します。
自分が感染した場合は友達の友達まで感染する、ただしワクチンを打っている人には伝染らない、ということです。
※以下の例ではワクチン接種を受けられる人は6名とします
NetworkXを使って感染症の広がりを可視化する
ネットワーク分析でよく使われるZacharyの空手クラブを例にして考えます。
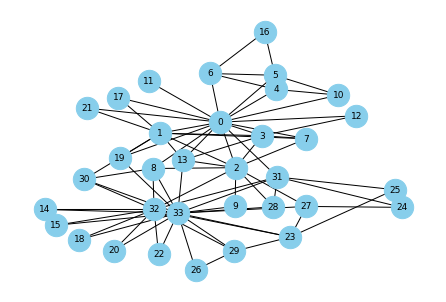
▼空手クラブのネットワーク構造を可視化する
# Zacharyの空手クラブ:1970年代のある米国大学における空手クラブの34人のメンバーの交友関係を示すソーシャルネットワーク。 # 余談:0番と33番(部長と師範)の仲が悪く、派閥をつくっている。 G = nx.karate_club_graph() pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color="skyblue", font_color="black")
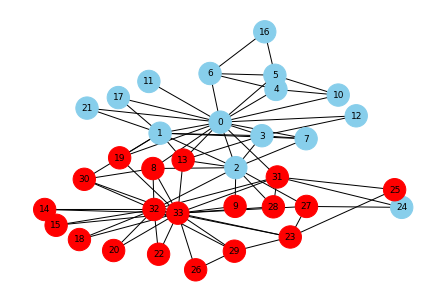
ワクチンが無い場合
最初の感染者を番号28の人として感染の広がりを確認してみます。 この場合、なんと25人が感染します。
▼感染者の数を求める
# 最初の感染者を決める start_node = 28 # 最初の感染者の隣の人 first_step = list(nx.single_source_shortest_path(G, source=start_node, cutoff=1)) # 最初の感染者の隣の人の隣の人 second_step = [] for node in first_step: second_step.extend(list(nx.single_source_shortest_path(G, source=node, cutoff=1))) second_step = list(set(second_step + first_step)) # 感染者数, 全体の人数 len(second_step), len(G.nodes)
▼感染の広がりを可視化する
# 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")

ワクチン接種者をランダムに選んだ場合
次に、ワクチンがある場合を考えます。ただし、ワクチン接種者はランダムに6名選ばれます。
このとき、最初に感染する人を任意に選んだ場合、感染者数の平均は何人になるのかを見てみます。
▼関数の準備
# ワクチン接種者を除外して感染した人をリストアップする関数 def infected_count(start_node, vaccinated_list): # ワクチン接種者を除外 if start_node in vaccinated_list: return [] else: # 最初の感染者を決める start_node = start_node # 最初の感染者の隣の人 first_step = list(nx.single_source_shortest_path(G, source=start_node, cutoff=1)) # ワクチン接種者を除外 first_step = list(set(first_step) - set(vaccinated_list)) # 最初の感染者の隣の人の隣の人 second_step = [] for node in first_step: second_step.extend(list(nx.single_source_shortest_path(G, source=node, cutoff=1))) # ワクチン接種者を除外 second_step = list(set(second_step) - set(vaccinated_list)) # 感染者数 return second_step
▼番号0~5にワクチンを接種させる。
vaccinated_list = [0,1,2,3,4,5] second_step = infected_count(start_node, vaccinated_list)
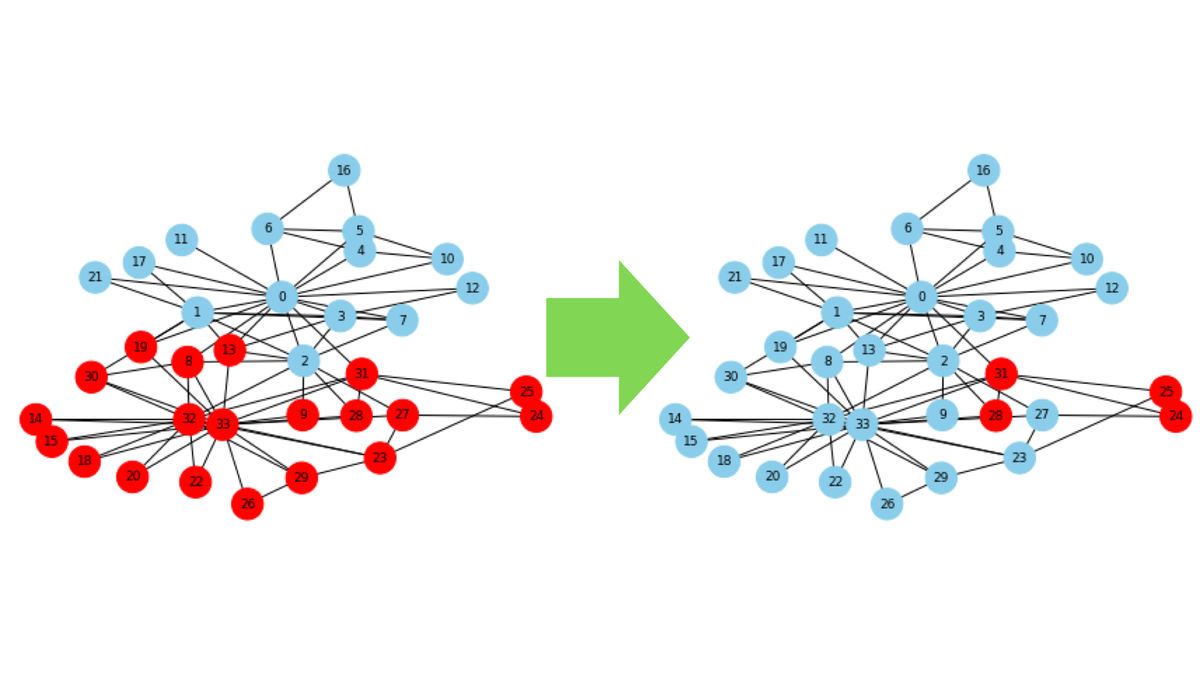
▼最初の感染者は28番のまま。感染の広がりはどうなる?
# 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
# 感染者数, 全体の人数 len(second_step), len(G.nodes)
感染者は19人となりました。
上の状況を一般化しましょう。
最初に感染する人を任意に選んだ場合、感染者数の平均は何人になるでしょうか?
# 感染者数の平均 value_list = [] for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) np.mean(value_list)
10.705882352941176 となり、約10.7人が感染することがわかりました。
次数中心性の大きい順にワクチン接種対象者を選んだ場合
次数中心性の大きい人から順にワクチンを接種してもらいます。
ワクチン接種者をランダムに選んだ場合とくらべて、感染者数の平均はどうなるでしょうか?
# 次数中心性の大きい人上位6名を選ぶ degree_centers = nx.degree_centrality(G) degree_centers_list = list(pd.DataFrame(sorted(degree_centers.items(), key=lambda x: x[1], reverse=True)[:6])[0]) vaccinated_list = degree_centers_list second_step = infected_count(start_node, vaccinated_list) # 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
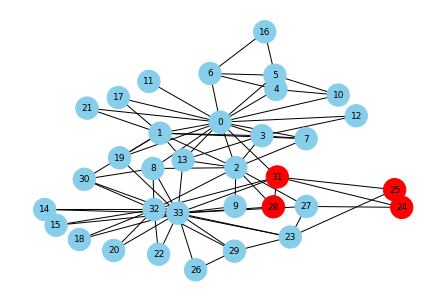
おお!感染者がすごい減ってる!
最初に感染する人を任意に取ってきて、感染者数の平均を求めましょう。
# 感染者数の平均
# 適当に選んだ場合よりも感染者が少ない!
value_list = []
for i in G.nodes():
value_list.append(len(infected_count(i, vaccinated_list)))
np.mean(value_list)
2.5294117647058822 という結果が出ました。約2.5人!
ランダムに選んだ場合の10.7人と比べると、格段に効果的ですね。
媒介中心性の大きい順にワクチン接種対象者を選んだ場合
媒介中心性を使った場合も見てみましょう。
# 媒介中心性の大きい人上位6名を選ぶ between_centers = nx.betweenness_centrality(G) between_centers_list = list(pd.DataFrame(sorted(between_centers.items(), key=lambda x: x[1], reverse=True)[:6])[0]) vaccinated_list = between_centers_list second_step = infected_count(start_node, vaccinated_list) # 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
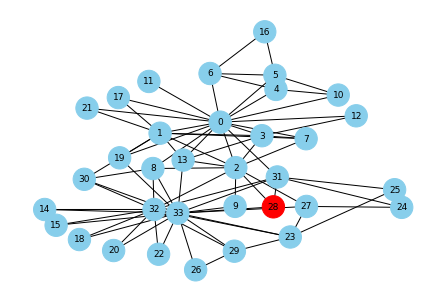
偶然にも最初に感染した人から全く感染が広がらない結果となりました。平均はどうでしょうか?
# 感染者数の平均 # 適当に選んだ場合よりも感染者が少ない!(次数中心性の場合よりは多い) value_list = [] for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) np.mean(value_list)
3.9411764705882355 となったので、次数中心性を使った場合よりは多いですが、ランダムにワクチン接種者を選ぶよりはだいぶマシな結果です。
中心性を使うメリット
実は中心性の考え方を使わなくても、ワクチン接種者の全パターンを列挙して計算すれば、最も感染拡大が少なくなるワクチン接種者リストを作ることができます。しかし、計算時間がめちゃくちゃ長い!
よって、中心性を用いた方が少ない計算量で効果的なワクチン配置を見つけるのに役立ちそうです。
ちなみに、次数中心性と媒介中心性のどちらが良いかは場合によるそうです。
ネットワークの構造がわからない場合はどうすればいい?
ここまでは、ネットワークの構造(人間関係)が既知であると仮定してきましたが、実社会でこれを把握するのは難しいです。
このとき、どんな方法でワクチン接種者(6人)を決めるのが良いでしょうか? ランダムに6人を選んでくるしか無いのでしょうか?
実は、ランダムに6人を選ぶ(random法)よりも、ランダムに選んだ各6人と繋がっている人の中からランダムに各1人を選んだ方が(random acquaintances法)、感染拡大を抑えられます。
これは、ランダムに選ばれた人の次数よりも、ランダムに選ばれた人のランダムな接続先の次数の方が大きくなるという多くのネットワーク上に現れる性質に基づいているそうです。
▼ランダムに6人を選ぶ場合
# ランダムに6人を選ぶ value_list = [] for k in range(1000): random.seed(17 * k) vaccinated_list = random.sample(list(G.nodes), 6) # 感染者数の平均 for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) value_list.append(np.mean(value_list)) np.mean(value_list)
結果:
13.18401066258339
▼ランダムに選んだ6人と隣接している人をランダムに1人ずつ選ぶ
# ランダムに選んだ6人と隣接している人をランダムに1人ずつ選ぶ value_list = [] for k in range(1000): random.seed(17 * k) # まずはランダムに6人選ぶ random_list = random.sample(list(G.nodes), 6) vaccinated_list = [] for node in random_list: # 6人のうちの1人の隣接している人のリスト candidate_pool = list(nx.single_source_shortest_path(G, source=node, cutoff=1)) if list(set(candidate_pool) - set(vaccinated_list)) == []: # 隣接している人全員がすでにワクチン接種対象となっていた場合、全員の中からワクチン接種対象者を除外してランダムに1人選ぶ。 new_pool = list(set(G.nodes()) - set(vaccinated_list)) vaccinated_node = random.sample(new_pool, 1) else: candidate_pool = list(set(candidate_pool) - set(vaccinated_list)) # 隣接している人のうち1人でもすでにワクチン接種対象でない場合、その中からランダムに1人選んでワクチン接種対象者とする。 vaccinated_node = random.sample(candidate_pool, 1) vaccinated_list.append(vaccinated_node[0]) # 感染者数の平均 for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) value_list.append(np.mean(value_list)) np.mean(value_list)
結果:
9.665484465359452
よって、random法が13.1人 > random acquaintances法が9.7人 となったため、後者の方が平均感染者数は小さいです。
【NetworkX】Girvan–Newmanアルゴリズムでコミュニティを抽出(台北MRTを例にして)
この記事では、NetworkXを使ったネットワークの中のコミュニティ抽出の手法を、台北の地下鉄を例にして解説します。
実際に分割されたコミュニティの可視化についてもコードを載せておきます。
Girvan–Newmanアルゴリズムとは?
Girvan–Newmanアルゴリズムはコミュニティを検出するアルゴリズムです。
手順はシンプルで、
- ネットワーク内のすべてのエッジの媒介中間性を計算する
- 最も媒介中間性が大きいエッジを削除する
- 削除した状態で再びすべてのエッジの媒介中間性を計算する
- エッジがなくなるまでステップ2~3を繰り返す
というものです。詳しい説明は以下の論文に書いてあります。
- Calculate the betweenness for all edges in the network.
- Remove the edge with the highest betweenness.
- Recalculate betweennesses for all edges affected by the removal.
- Repeat from step 2 until no edges remain.
Community structure in social and biological networks
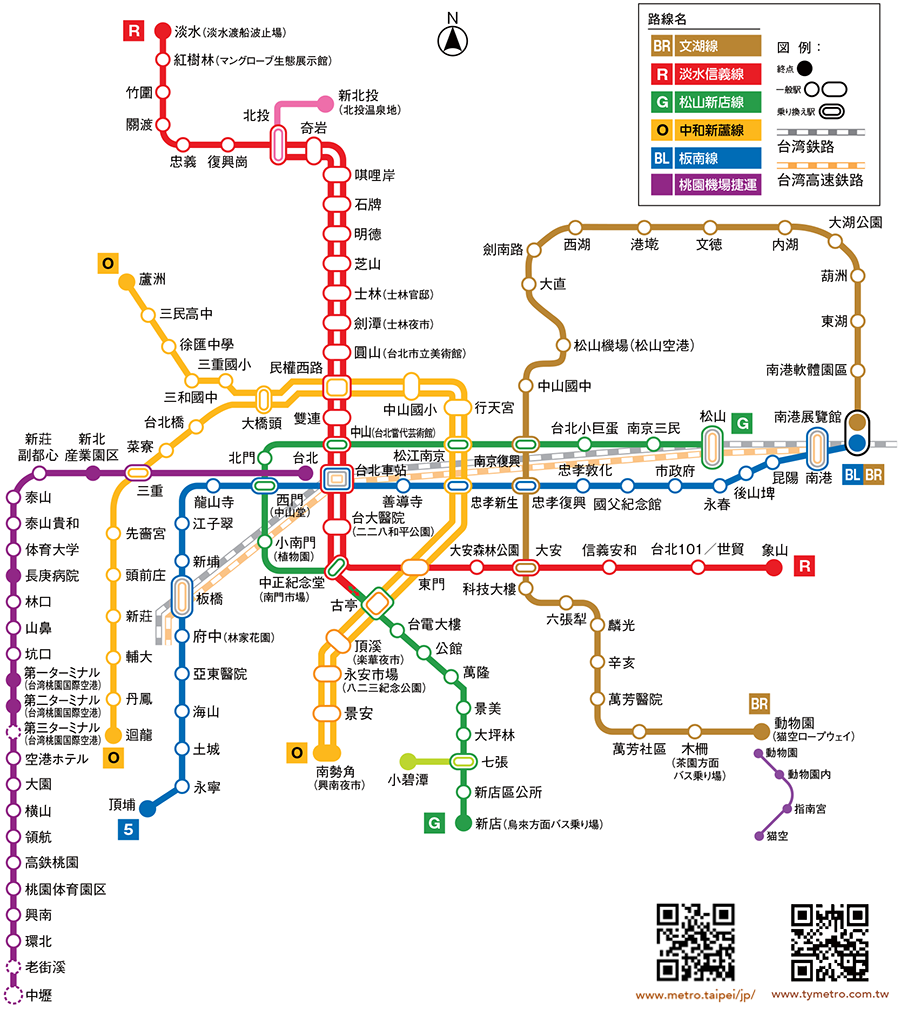
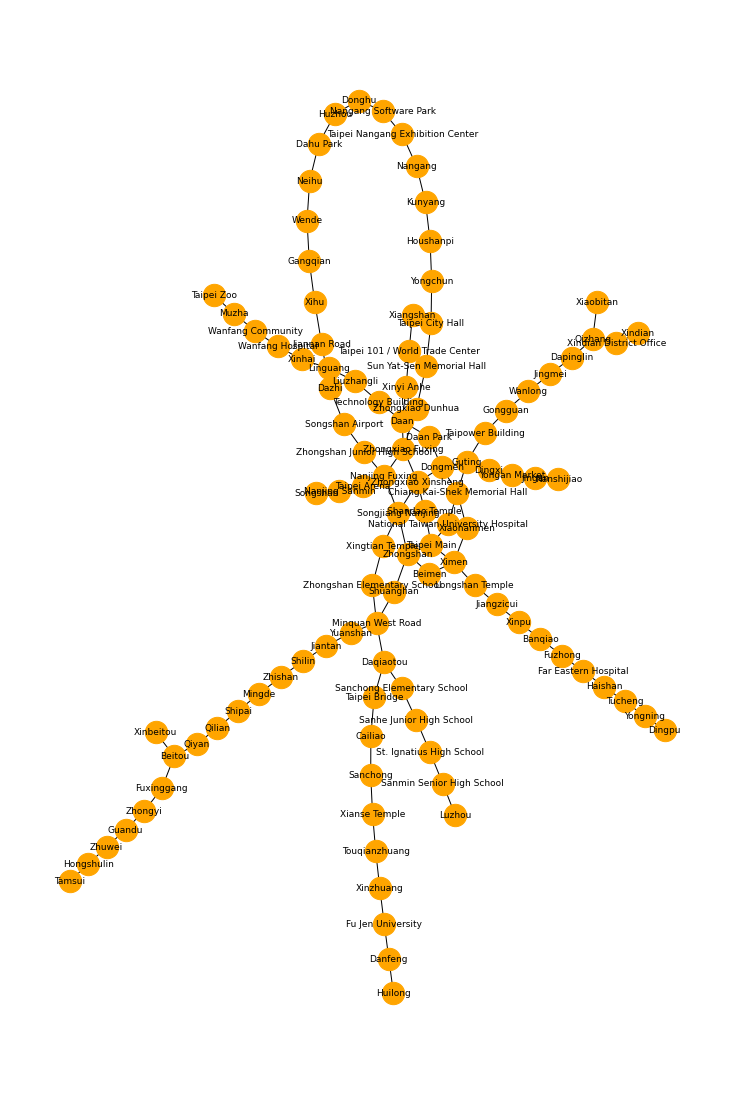
台北MRTの路線図をNetworkXで描画する
台北のMRTの路線図を描いてみます。これをGirvan–Newmanアルゴリズムでコミュニティ分割します。
 画像:
画像:import matplotlib.pyplot as plt import networkx as nx import numpy as np from networkx.algorithms.community.centrality import girvan_newman import itertools
隣の駅の組み合わせをリスト化します。これ手作業でやったのでめちゃくちゃ大変でした(笑)
※桃園機場MRTは省いています
edge_list = [ ('Dingpu', 'Yongning'), ('Yongning', 'Tucheng'), ('Tucheng', 'Haishan'), ('Haishan', 'Far Eastern Hospital'), ('Far Eastern Hospital', 'Fuzhong'), ('Fuzhong', 'Banqiao'), ('Banqiao', 'Xinpu'), ('Xinpu', 'Jiangzicui'), ('Jiangzicui', 'Longshan Temple'), ('Longshan Temple', 'Ximen'), ('Ximen', 'Taipei Main'), ('Taipei Main', 'Shandao Temple'), ('Shandao Temple', 'Zhongxiao Xinsheng'), ('Zhongxiao Xinsheng', 'Zhongxiao Fuxing'), ('Zhongxiao Fuxing', 'Zhongxiao Dunhua'), ('Zhongxiao Dunhua', 'Sun Yat-Sen Memorial Hall'), ('Sun Yat-Sen Memorial Hall', 'Taipei City Hall'), ('Taipei City Hall', 'Yongchun'), ('Yongchun', 'Houshanpi'), ('Houshanpi', 'Kunyang'), ('Kunyang', 'Nangang'), ('Nangang', 'Taipei Nangang Exhibition Center'), ('Taipei Nangang Exhibition Center', 'Nangang Software Park'), ('Nangang Software Park', 'Donghu'), ('Donghu', 'Huzhou'), ('Huzhou', 'Dahu Park'), ('Dahu Park', 'Neihu'), ('Neihu', 'Wende'), ('Wende', 'Gangqian'), ('Gangqian', 'Xihu'), ('Xihu', 'Jiannan Road'), ('Jiannan Road', 'Dazhi'), ('Dazhi', 'Songshan Airport'), ('Songshan Airport', 'Zhongshan Junior High School'), ('Zhongshan Junior High School', 'Nanjing Fuxing'), ('Nanjing Fuxing', 'Zhongxiao Fuxing'), ('Zhongxiao Fuxing', 'Daan'), ('Daan', 'Technology Building'), ('Technology Building', 'Liuzhangli'), ('Liuzhangli', 'Linguang'), ('Linguang', 'Xinhai'), ('Xinhai', 'Wanfang Hospital'), ('Wanfang Hospital', 'Wanfang Community'), ('Wanfang Community', 'Muzha'), ('Muzha', 'Taipei Zoo'), ('Xiangshan', 'Taipei 101 / World Trade Center'), ('Taipei 101 / World Trade Center', 'Xinyi Anhe'), ('Xinyi Anhe', 'Daan'), ('Daan', 'Daan Park'), ('Daan Park', 'Dongmen'), ('Dongmen', 'Chiang Kai-Shek Memorial Hall'), ('Chiang Kai-Shek Memorial Hall', 'National Taiwan University Hospital'), ('National Taiwan University Hospital', 'Taipei Main'), ('Taipei Main', 'Zhongshan'), ('Zhongshan', 'Shuanglian'), ('Shuanglian', 'Minquan West Road'), ('Minquan West Road', 'Yuanshan'), ('Yuanshan', 'Jiantan'), ('Jiantan', 'Shilin'), ('Shilin', 'Zhishan'), ('Zhishan', 'Mingde'), ('Mingde', 'Shipai'), ('Shipai', 'Qilian'), ('Qilian', 'Qiyan'), ('Qiyan', 'Beitou'), ('Beitou', 'Xinbeitou'), ('Beitou', 'Fuxinggang'), ('Fuxinggang', 'Zhongyi'), ('Zhongyi', 'Guandu'), ('Guandu', 'Zhuwei'), ('Zhuwei', 'Hongshulin'), ('Hongshulin', 'Tamsui'), ('Nanshijiao', 'Jingan'), ('Jingan', 'Yongan Market'), ('Yongan Market', 'Dingxi'), ('Dingxi', 'Guting'), ('Guting', 'Dongmen'), ('Dongmen', 'Zhongxiao Xinsheng'), ('Zhongxiao Xinsheng', 'Songjiang Nanjing'), ('Songjiang Nanjing', 'Xingtian Temple'), ('Xingtian Temple', 'Zhongshan Elementary School'), ('Zhongshan Elementary School', 'Minquan West Road'), ('Minquan West Road', 'Daqiaotou'), ('Daqiaotou', 'Taipei Bridge'), ('Taipei Bridge', 'Cailiao'), ('Cailiao', 'Sanchong'), ('Sanchong', 'Xianse Temple'), ('Xianse Temple', 'Touqianzhuang'), ('Touqianzhuang', 'Xinzhuang'), ('Xinzhuang', 'Fu Jen University'), ('Fu Jen University', 'Danfeng'), ('Danfeng', 'Huilong'), ('Daqiaotou', 'Sanchong Elementary School'), ('Sanchong Elementary School', 'Sanhe Junior High School'), ('Sanhe Junior High School', 'St. Ignatius High School'), ('St. Ignatius High School', 'Sanmin Senior High School'), ('Sanmin Senior High School', 'Luzhou'), ('Xindian', 'Xindian District Office'), ('Xindian District Office', 'Qizhang'), ('Qizhang', 'Xiaobitan'), ('Qizhang', 'Dapinglin'), ('Dapinglin', 'Jingmei'), ('Jingmei', 'Wanlong'), ('Wanlong', 'Gongguan'), ('Gongguan', 'Taipower Building'), ('Taipower Building', 'Guting'), ('Guting', 'Chiang Kai-Shek Memorial Hall'), ('Chiang Kai-Shek Memorial Hall', 'Xiaonanmen'), ('Xiaonanmen', 'Ximen'), ('Ximen', 'Beimen'), ('Beimen', 'Zhongshan'), ('Zhongshan', 'Songjiang Nanjing'), ('Songjiang Nanjing', 'Nanjing Fuxing'), ('Nanjing Fuxing', 'Taipei Arena'), ('Taipei Arena', 'Nanjing Sanmin'),('Nanjing Sanmin', 'Songshan') ]
この隣の駅のリストをadd_edges_fromでグラフとして読み込み、描画してみます。
# グラフ作成 G = nx.Graph() G.add_edges_from(edge_list) # 描画 plt.figure(figsize=(10, 15)) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color="orange", font_color="black")
はい、こんな感じです。
▼NetworkXで描画した台北MRT路線図
媒介中心性を計算してみましょう。
大きい順にTop5を並べてみます。
between_centers = nx.betweenness_centrality(G) sorted(between_centers.items(), key=lambda x: x[1], reverse=True)[:5]
▼実行結果
>[('Minquan West Road', 0.4594251454769881),
> ('Songjiang Nanjing', 0.3815229530359139),
> ('Zhongshan', 0.32528654558279),
> ('Zhongxiao Fuxing', 0.3118468230176916),
> ('Nanjing Fuxing', 0.2861282548639271)]
民権西路(Minquan West Road)の媒介中心性が一番大きいですね。
感覚的には台北車站(Taipei Main Station)かなと思いましたがTop5にすらランクインしていませんでした。
路線図をコミュニティに分割する
期待としては、上で描画したグラフの上部にあるループや、下に伸びている3本の路線がそれぞれ分割されると良いなと。
girvan_newmanを使って、実際にコミュニティを分割するコードを書きます。
以下のコードのkは分割の数を表します。k=4にすると5つのコミュニティに分割されるわけです。
k = 4 comp = girvan_newman(G) for communities in itertools.islice(comp, k): list_community = [] for c in communities: list_community.append(list(c))
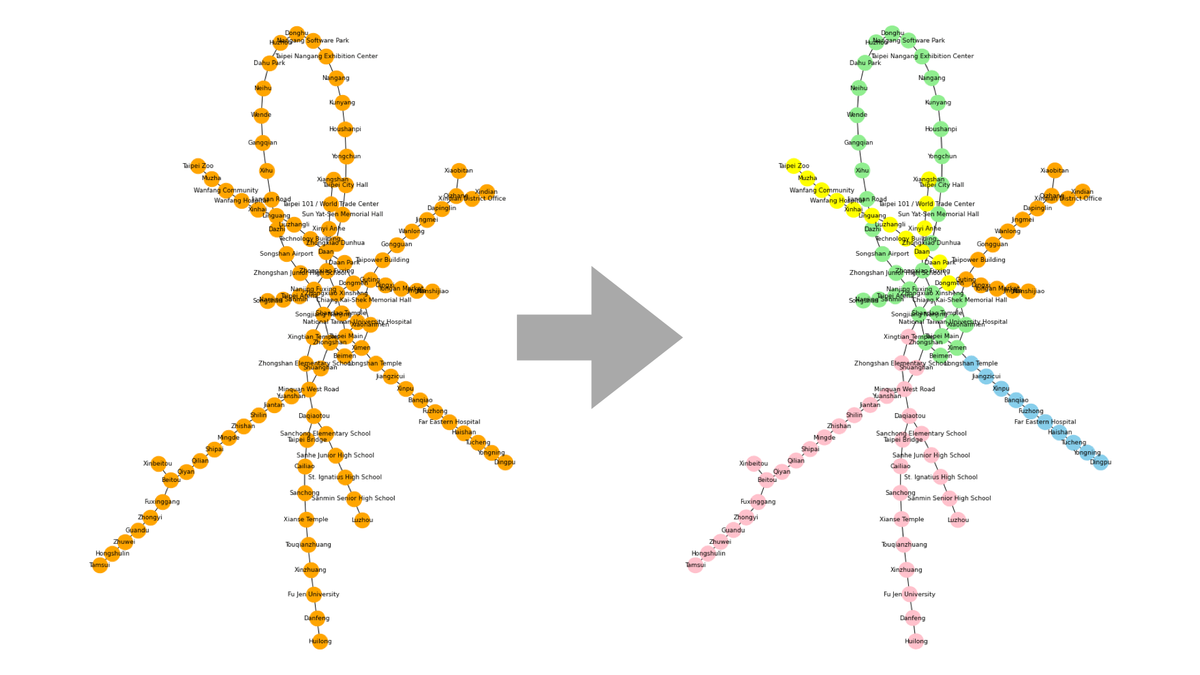
分割したそれぞれコミュニティに色付けをします。これでコミュニティをわかりやすく可視化できます。
color_map = [] for node in G.nodes(): if node in list_community[0]: color_map.append('skyblue') elif node in list_community[1]: color_map.append('lightgreen') elif node in list_community[2]: color_map.append('yellow') elif node in list_community[3]: color_map.append('pink') else: color_map.append('orange')
描画します!
plt.figure(figsize=(10, 15)) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
▼コミュニティ分割の可視化
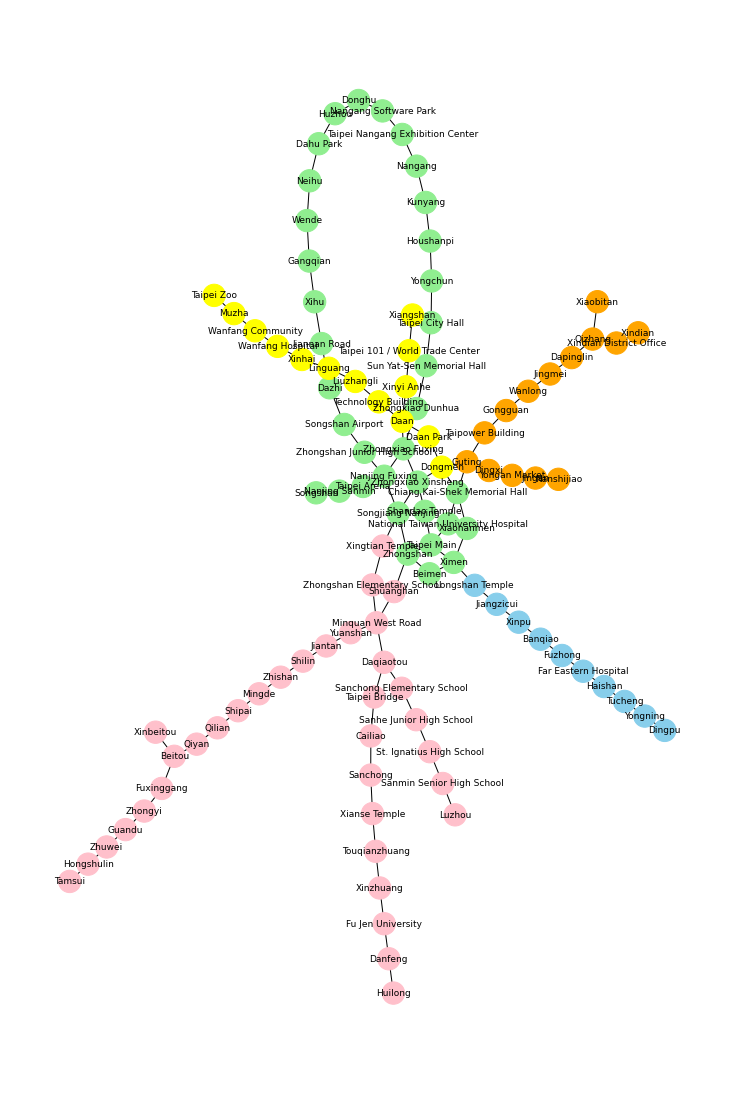
まあ、なんとなく期待通りの分割になりました。
まとめ
今回はGirvan–Newmanアルゴリズムを使ってみましたが、他にも様々なコミュニティ分割の手法があるので、また試してみたいと思います。
▼参考文献
pageviewapiを使ってWikipediaの記事のPV数をDailyで取得する(トレンド把握に便利!)
pageviewapiというWikipediaの任意の記事のPV数を取得するAPIを使って見たいと思います。
WikipediaのどんなページのPV数でも一気に調べられます。
これは何に便利かというと、知りたい事柄(例えば有名人、企業、地名など)がどの程度世間から関心を持たれているのかを時系列で把握することができます。
この記事では「新型コロナウイルス感染症」を例に、その関心のトレンドを見ていきます。
まず、pageviewapiのインストールと各ライブラリのimportです。
!pip install pageviewapi import pandas as pd import pageviewapi import pageviewapi.period import datetime from datetime import timedelta
次に、pageviewapiを実際に使ってみましょう。以下のように書きます。
ここで、pageにはWikipediaの正式なページ名(URLを見ればわかる)を指定するようにしましょう。
# 調べたいWikipediaのページを指定 page = "新型コロナウイルス感染症_(2019年)" # 調べたい日付範囲を指定 start_date = datetime.datetime.now() - timedelta(days=180+1) end_date = datetime.datetime.now() - timedelta(days=1) # 日付は8桁の形式になおしておく start_date = start_date.strftime('%Y%m%d') end_date = end_date.strftime('%Y%m%d') # pageviewapi をつってPVを取得する wiki_dict = pageviewapi.per_article( 'ja.wikipedia', page, start_date, end_date, access='all-access', agent='all-agents', granularity='daily') # 格納されたデータの0番目の要素を取り出す wiki_dict['items'][0]
上のコードを実行するとこんな結果が返ってきます。
これは2022年1月25日のWikipediaの新型コロナウイルス感染症の日本語の記事が3,303PVあったことを意味しています。
{'access': 'all-access',
'agent': 'all-agents',
'article': '新型コロナウイルス感染症_(2019年)',
'granularity': 'daily',
'project': 'ja.wikipedia',
'timestamp': '2022012500',
'views': 3303}
最後に、DailyのPV数を取得する関数を定義して、直近180日間のPV推移をグラフに描いてみましょう。
def get_pv(page, start_date, end_date): pv_dict = pageviewapi.per_article('ja.wikipedia', page, start_date, end_date, access='all-access', agent='all-agents', granularity='daily') blank_list = [] for i in range(len(pd.DataFrame(pv_dict))): date = pd.DataFrame(pv_dict)['items'][i]['timestamp'] date = date[0:4] + "-" + date[4:6] + "-" + date[6:8] pv = pd.DataFrame(pv_dict)['items'][i]['views'] blank_list.append([date, pv]) df = pd.DataFrame(blank_list).rename(columns = {0: 'date', 1: 'pv'}) df['date'] = pd.to_datetime(df['date']) return df get_pv(page, start_date, end_date).set_index("date")['pv'].plot()
するとこんなグラフになります。
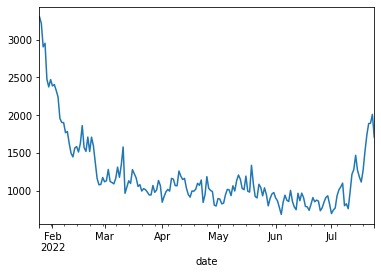
このグラフをどのように解釈するかは読み方次第ですが、使い方によっては有用なデータになると思います。
公式リファレンス: pypi.org
【Python】pandasのgroupbyで複数の統計量(平均、中央値など)を同時に取る
pandasでgroupbyを使って集計をする際に、この量に関しては平均を、また別の量については中央値を取りたい場合などに使える方法です。
まず、DataFrameを定義します。
男女の身長と体重が記録されているとしましょう。
import pandas as pd sample_df = pd.DataFrame({ "gender": ["F", "F", "F", "M", "M", "M"], "height": [158, 162, 155, 175, 163, 178], "weight": [45, 50, 40, 72, 66, 80] })
ここで、性別によってgroupbyして身長と体重の平均をとりたい場合は以下のようになります。
sample_df.groupby(['gender'])[["height", "weight"]].mean()
結果はこんな感じです。
| height | weight | |
|---|---|---|
| gender | ||
| F | 158.333333 | 45.000000 |
| M | 172.000000 | 72.666667 |
これを例えば、身長については中央値を体重については平均を取りたい場合は、次のように書けば良いです。
sample_df.groupby(['gender']).agg({"height": "median", "weight": "mean"})
結果は以下の通り。
| height | weight | |
|---|---|---|
| gender | ||
| F | 158.0 | 45.000000 |
| M | 175.0 | 72.666667 |
【NetworkX】ネットワークの中の最大の連結成分を取り出す【Python】
networkxを使って遊んでみます。
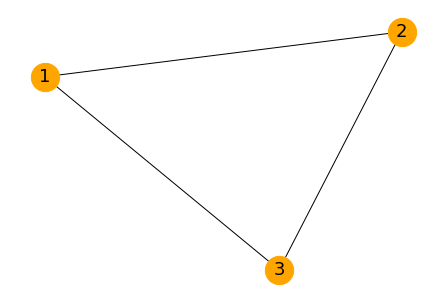
下の図のようなネットワーク(グラフ)が与えられたとき、この中の最大の連結成分を取り出します。
見ての通り、{4, 5, 6, 7, 8}が最大の連結成分になります。
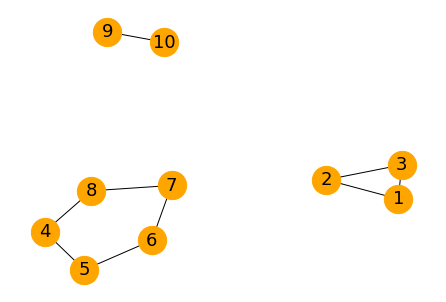
まずは、ネットワークを描画してみます。
import networkx as nx edge_list = [ (1, 2), (2, 3), (3, 1), (4, 5), (5, 6), (6, 7), (7, 8), (8, 4), (9, 10) ] # グラフ作成 G = nx.Graph() G.add_edges_from(edge_list) # 描画 pos = nx.spring_layout(G, k=0.7) nx.draw(G, pos, with_labels=True, font_size=18, node_size=800, node_color="orange", font_color="black")
nx.connected_componentsを使って、最大の連結成分を求めます。
largest_cc = max(nx.connected_components(G), key=len) largest_cc >>>{4, 5, 6, 7, 8}
この通り、{4, 5, 6, 7, 8}が出てきました。
また、各連結成分をグラフとして取り出したい場合は以下のように書きます。
試しに0番目の部分グラフを描画してみます。
ちなみに、0番目が最大の連結成分とは限らないです。
# 各連結成分をグラフとして取り出す S = [G.subgraph(c).copy() for c in nx.connected_components(G)] # 試しにS[0]を描画 pos = nx.spring_layout(S[0], k=0.7) nx.draw(S[0], pos, with_labels=True, font_size=18, node_size=800, node_color="orange", font_color="black")
こんな感じになりました。
今回はこのへんで!
【SQL】BigQueryで月末の日付を取得する
SQLで月末の日付を知りたい時の処理です。
2021-05-21 を 2021-05-31にしたいということですね。
DATE_TRUNC と DATE_ADD と DATE_SUB を使うというだけなんですが、一応やり方を残しておきます。
SELECT DATE_SUB(DATE_ADD(DATE_TRUNC('2021-05-21', MONTH), INTERVAL 1 MONTH), INTERVAL 1 DAY) AS monthEnd
【Python】OpenCVでGoogle Driveにある画像ファイルを読み込む&表示する方法
画像処理で遊びたくなったので、画像を読み込んで表示する方法を備忘録的に残しておきます。
OpenCVを使います。
まずは、OpenCVやNupmy、Matplotlibなどをimportして、さらにGoogle Driveをマウントしておきます。
import cv2 import matplotlib.pyplot as plt import numpy as np from PIL import Image %matplotlib inline from google.colab import drive drive.mount('/content/gdrive')
そして、Google Driveのpathを指定して画像を読み込み&描画します。
#入力ファイルのパスを指定 jpg_image = "/content/gdrive/My Drive/image/01.jpeg" #入力画像の表示 plt.show(plt.imshow(np.asarray(Image.open(jpg_image))))
これだけですね!以上です!