ネットワーク分析を用いて感染症の制御を考えてみる(経済セミナー 2020年12月・2021年1月号より)
ここでは、経済セミナー 2020年12月・2021年1月号に掲載のあった「中心性を使った感染症の制御(小蔵正輝)」という記事を、実際にPythonで(NetworkXを使って)コードを書きながら解説します。
以下で説明するような問題設定下においては、ネットワークの中心性を上手く使うことで感染症の拡大を抑えられるという、なかなか面白い内容でした。
NetworkXの勉強がてらコードを書いていきたいと思います。
問題設定
ある社会集団において、社会的なつながりを介して感染症が広がる状況を考えます。
家族や友達にしか感染症が伝染らないというような状況ですね。
そのような状況下で、「ワクチン接種を受けられる人数が限られているとき、ネットワーク内の誰にワクチンを打てば感染拡大を抑えられるか?」というのがここで考える問題です。
感染のルール
感染症が伝播するルールを設定します。
経済セミナーの記事からそのまま引用します。
自分が感染した場合は友達の友達まで感染する、ただしワクチンを打っている人には伝染らない、ということです。
※以下の例ではワクチン接種を受けられる人は6名とします
NetworkXを使って感染症の広がりを可視化する
ネットワーク分析でよく使われるZacharyの空手クラブを例にして考えます。
▼空手クラブのネットワーク構造を可視化する
# Zacharyの空手クラブ:1970年代のある米国大学における空手クラブの34人のメンバーの交友関係を示すソーシャルネットワーク。 # 余談:0番と33番(部長と師範)の仲が悪く、派閥をつくっている。 G = nx.karate_club_graph() pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color="skyblue", font_color="black")
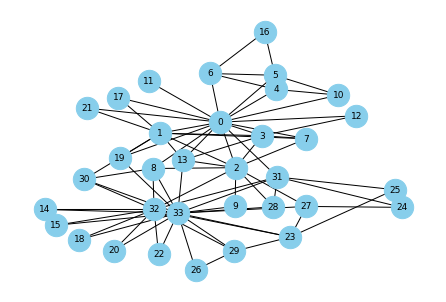
ワクチンが無い場合
最初の感染者を番号28の人として感染の広がりを確認してみます。 この場合、なんと25人が感染します。
▼感染者の数を求める
# 最初の感染者を決める start_node = 28 # 最初の感染者の隣の人 first_step = list(nx.single_source_shortest_path(G, source=start_node, cutoff=1)) # 最初の感染者の隣の人の隣の人 second_step = [] for node in first_step: second_step.extend(list(nx.single_source_shortest_path(G, source=node, cutoff=1))) second_step = list(set(second_step + first_step)) # 感染者数, 全体の人数 len(second_step), len(G.nodes)
▼感染の広がりを可視化する
# 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")

ワクチン接種者をランダムに選んだ場合
次に、ワクチンがある場合を考えます。ただし、ワクチン接種者はランダムに6名選ばれます。
このとき、最初に感染する人を任意に選んだ場合、感染者数の平均は何人になるのかを見てみます。
▼関数の準備
# ワクチン接種者を除外して感染した人をリストアップする関数 def infected_count(start_node, vaccinated_list): # ワクチン接種者を除外 if start_node in vaccinated_list: return [] else: # 最初の感染者を決める start_node = start_node # 最初の感染者の隣の人 first_step = list(nx.single_source_shortest_path(G, source=start_node, cutoff=1)) # ワクチン接種者を除外 first_step = list(set(first_step) - set(vaccinated_list)) # 最初の感染者の隣の人の隣の人 second_step = [] for node in first_step: second_step.extend(list(nx.single_source_shortest_path(G, source=node, cutoff=1))) # ワクチン接種者を除外 second_step = list(set(second_step) - set(vaccinated_list)) # 感染者数 return second_step
▼番号0~5にワクチンを接種させる。
vaccinated_list = [0,1,2,3,4,5] second_step = infected_count(start_node, vaccinated_list)
▼最初の感染者は28番のまま。感染の広がりはどうなる?
# 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
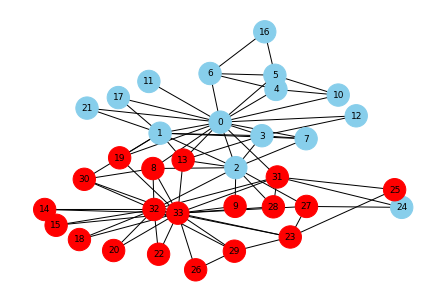
# 感染者数, 全体の人数 len(second_step), len(G.nodes)
感染者は19人となりました。
上の状況を一般化しましょう。
最初に感染する人を任意に選んだ場合、感染者数の平均は何人になるでしょうか?
# 感染者数の平均 value_list = [] for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) np.mean(value_list)
10.705882352941176 となり、約10.7人が感染することがわかりました。
次数中心性の大きい順にワクチン接種対象者を選んだ場合
次数中心性の大きい人から順にワクチンを接種してもらいます。
ワクチン接種者をランダムに選んだ場合とくらべて、感染者数の平均はどうなるでしょうか?
# 次数中心性の大きい人上位6名を選ぶ degree_centers = nx.degree_centrality(G) degree_centers_list = list(pd.DataFrame(sorted(degree_centers.items(), key=lambda x: x[1], reverse=True)[:6])[0]) vaccinated_list = degree_centers_list second_step = infected_count(start_node, vaccinated_list) # 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
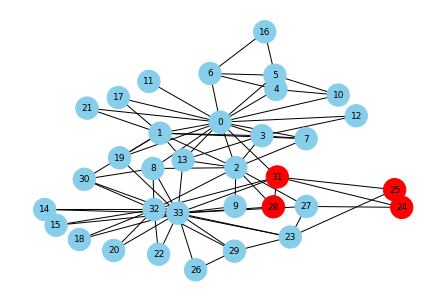
おお!感染者がすごい減ってる!
最初に感染する人を任意に取ってきて、感染者数の平均を求めましょう。
# 感染者数の平均
# 適当に選んだ場合よりも感染者が少ない!
value_list = []
for i in G.nodes():
value_list.append(len(infected_count(i, vaccinated_list)))
np.mean(value_list)
2.5294117647058822 という結果が出ました。約2.5人!
ランダムに選んだ場合の10.7人と比べると、格段に効果的ですね。
媒介中心性の大きい順にワクチン接種対象者を選んだ場合
媒介中心性を使った場合も見てみましょう。
# 媒介中心性の大きい人上位6名を選ぶ between_centers = nx.betweenness_centrality(G) between_centers_list = list(pd.DataFrame(sorted(between_centers.items(), key=lambda x: x[1], reverse=True)[:6])[0]) vaccinated_list = between_centers_list second_step = infected_count(start_node, vaccinated_list) # 色指定 color_map = [] for node in G.nodes(): if node in second_step: color_map.append('red') else: color_map.append('skyblue') # ステップ2までの感染者(赤) pos = nx.kamada_kawai_layout(G) nx.draw(G, pos, with_labels=True, font_size=9, node_size=500, node_color=color_map, font_color="black")
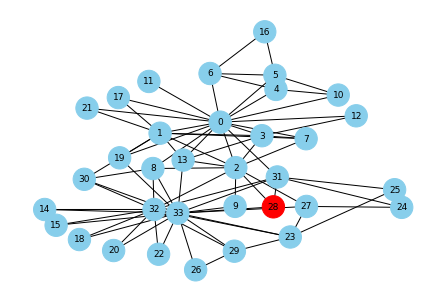
偶然にも最初に感染した人から全く感染が広がらない結果となりました。平均はどうでしょうか?
# 感染者数の平均 # 適当に選んだ場合よりも感染者が少ない!(次数中心性の場合よりは多い) value_list = [] for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) np.mean(value_list)
3.9411764705882355 となったので、次数中心性を使った場合よりは多いですが、ランダムにワクチン接種者を選ぶよりはだいぶマシな結果です。
中心性を使うメリット
実は中心性の考え方を使わなくても、ワクチン接種者の全パターンを列挙して計算すれば、最も感染拡大が少なくなるワクチン接種者リストを作ることができます。しかし、計算時間がめちゃくちゃ長い!
よって、中心性を用いた方が少ない計算量で効果的なワクチン配置を見つけるのに役立ちそうです。
ちなみに、次数中心性と媒介中心性のどちらが良いかは場合によるそうです。
ネットワークの構造がわからない場合はどうすればいい?
ここまでは、ネットワークの構造(人間関係)が既知であると仮定してきましたが、実社会でこれを把握するのは難しいです。
このとき、どんな方法でワクチン接種者(6人)を決めるのが良いでしょうか? ランダムに6人を選んでくるしか無いのでしょうか?
実は、ランダムに6人を選ぶ(random法)よりも、ランダムに選んだ各6人と繋がっている人の中からランダムに各1人を選んだ方が(random acquaintances法)、感染拡大を抑えられます。
これは、ランダムに選ばれた人の次数よりも、ランダムに選ばれた人のランダムな接続先の次数の方が大きくなるという多くのネットワーク上に現れる性質に基づいているそうです。
▼ランダムに6人を選ぶ場合
# ランダムに6人を選ぶ value_list = [] for k in range(1000): random.seed(17 * k) vaccinated_list = random.sample(list(G.nodes), 6) # 感染者数の平均 for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) value_list.append(np.mean(value_list)) np.mean(value_list)
結果:
13.18401066258339
▼ランダムに選んだ6人と隣接している人をランダムに1人ずつ選ぶ
# ランダムに選んだ6人と隣接している人をランダムに1人ずつ選ぶ value_list = [] for k in range(1000): random.seed(17 * k) # まずはランダムに6人選ぶ random_list = random.sample(list(G.nodes), 6) vaccinated_list = [] for node in random_list: # 6人のうちの1人の隣接している人のリスト candidate_pool = list(nx.single_source_shortest_path(G, source=node, cutoff=1)) if list(set(candidate_pool) - set(vaccinated_list)) == []: # 隣接している人全員がすでにワクチン接種対象となっていた場合、全員の中からワクチン接種対象者を除外してランダムに1人選ぶ。 new_pool = list(set(G.nodes()) - set(vaccinated_list)) vaccinated_node = random.sample(new_pool, 1) else: candidate_pool = list(set(candidate_pool) - set(vaccinated_list)) # 隣接している人のうち1人でもすでにワクチン接種対象でない場合、その中からランダムに1人選んでワクチン接種対象者とする。 vaccinated_node = random.sample(candidate_pool, 1) vaccinated_list.append(vaccinated_node[0]) # 感染者数の平均 for i in G.nodes(): value_list.append(len(infected_count(i, vaccinated_list))) value_list.append(np.mean(value_list)) np.mean(value_list)
結果:
9.665484465359452
よって、random法が13.1人 > random acquaintances法が9.7人 となったため、後者の方が平均感染者数は小さいです。